Unsupervised pretraining has been transformative in many supervised domains. However, applying such ideas to reinforcement learning (RL) presents a unique challenge in that fine-tuning does not involve mimicking task-specific data, but rather exploring and locating the solution through iterative self-improvement.
In this work, we study how unlabeled offline trajectory data can be leveraged to learn efficient exploration strategies. While prior data can be used to pretrain a set of low-level skills, or as additional off-policy data for online RL, it has been unclear how to combine these ideas effectively for online exploration.
Our method SUPE (Skills from Unlabeled Prior data for Exploration) demonstrates that a careful combination of these ideas compounds their benefits. Our method first extracts low-level skills using a variational autoencoder (VAE), and then pseudo-labels unlabeled trajectories with optimistic rewards and high-level action labels, transforming prior data into high-level, task-relevant examples that encourage novelty-seeking behavior. Finally, SUPE uses these transformed examples as additional off-policy data for online RL to learn a high-level policy that composes pretrained low-level skills to explore efficiently. In our experiments, SUPE consistently outperforms prior strategies across a suite of 42 long-horizon, sparse-reward tasks.
Our method uses unlabelled prior data in two distinct ways to address two different exploration challenges.

With no knowledge of the reward function, the RL agent does not know which directions to explore and naively sampling actions from the agent results in temporally incoherent exploration. In many long-horizon tasks, this can lead to difficulty discovering high-reward states, resulting in high sample complexity. How can we structure exploration with temporally coherent actions?
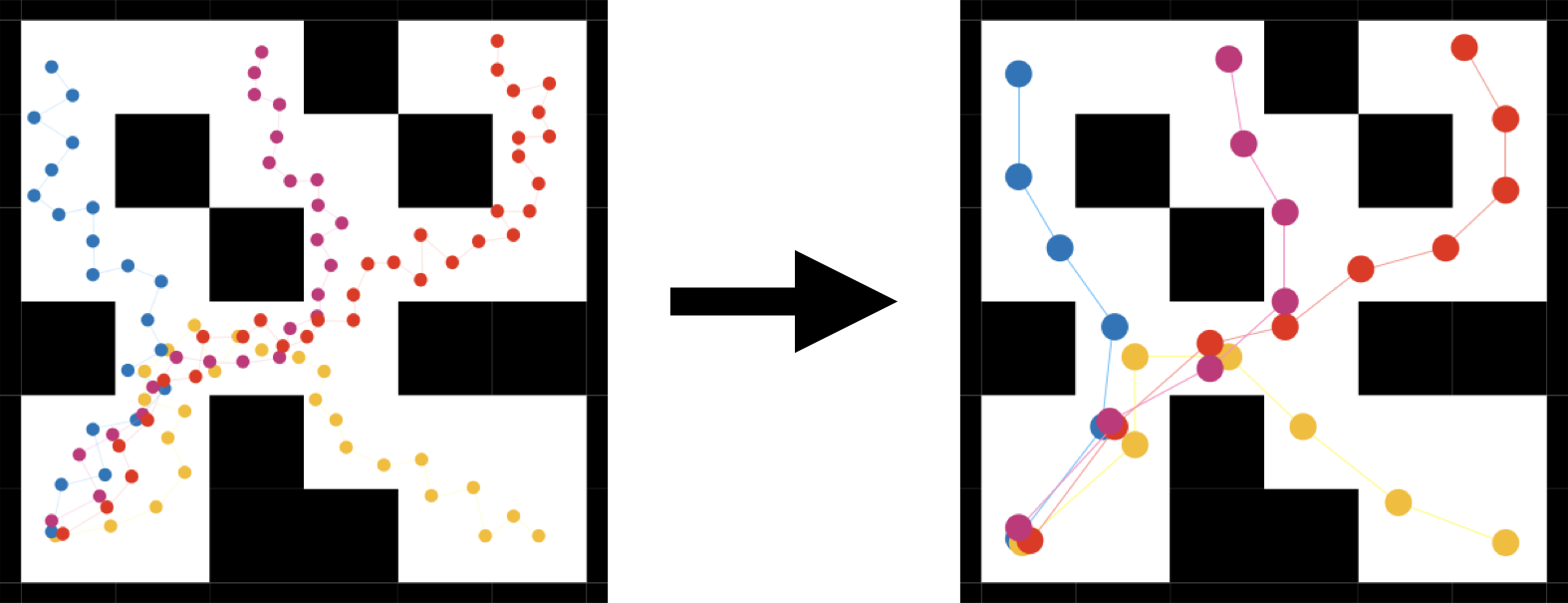
To structure online exploration, we extract skills from the data to capture low-level, task-agnostic behaviors. We pretrain skills using a VAE, where the decoder serves as the skill policy, reconstructing dataset trajectory segments conditioned on the skill latent and current observation. This helps keep exploration within the space of useful behaviors present in the prior data — ie. moving in different directions within a maze, rather than applying random forces to the agent.
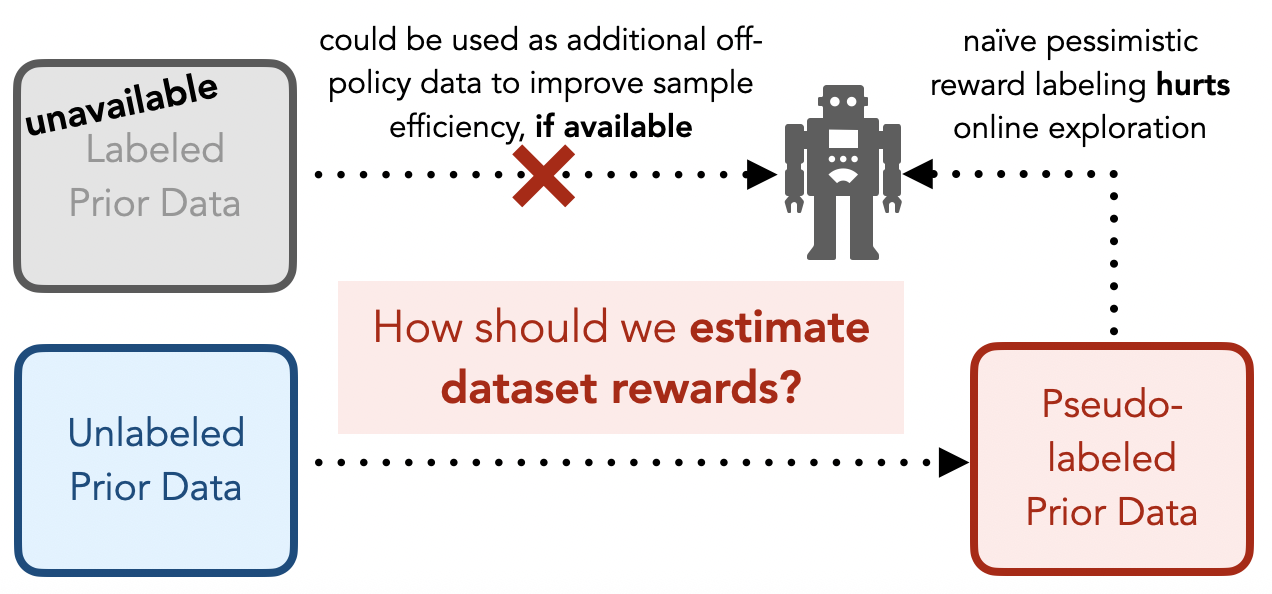
Labelled prior data can accelerate online learning by identifying high reward behaviors. However, task-specific prior data can be costly to collect, and is often not available for the task at hand. Naïvely learning a reward model online to obtain estimated rewards for the offline data works poorly, since estimates for offline transitions not in the online data distribution are pessimistic, discouraging exploration. How should we estimate dataset rewards?





To encourage online exploration, we label dataset rewards optimistically and use relabelled transitions as extra off-policy data during online learning. More concretely, we estimate the reward using a reward model learned online, plus an uncertainty bonus estimated using RND. Additionally, we estimate the skill latent action of the offline trajectory segment using the encoder from the pre-trained VAE. This causes the entire offline data distribution to have an optimistic reward estimate, encouraging the agent to visit these areas.
Putting these two components together with online RL training, our method, SUPE, trains a high-level policy on a combination of the online replay buffer data and optimistically labeled offline data to output a high-level action every H steps. The pre-trained policy enables temporally coherent exploration and the optimistic data labeling improves the sample efficiency of policy learning.
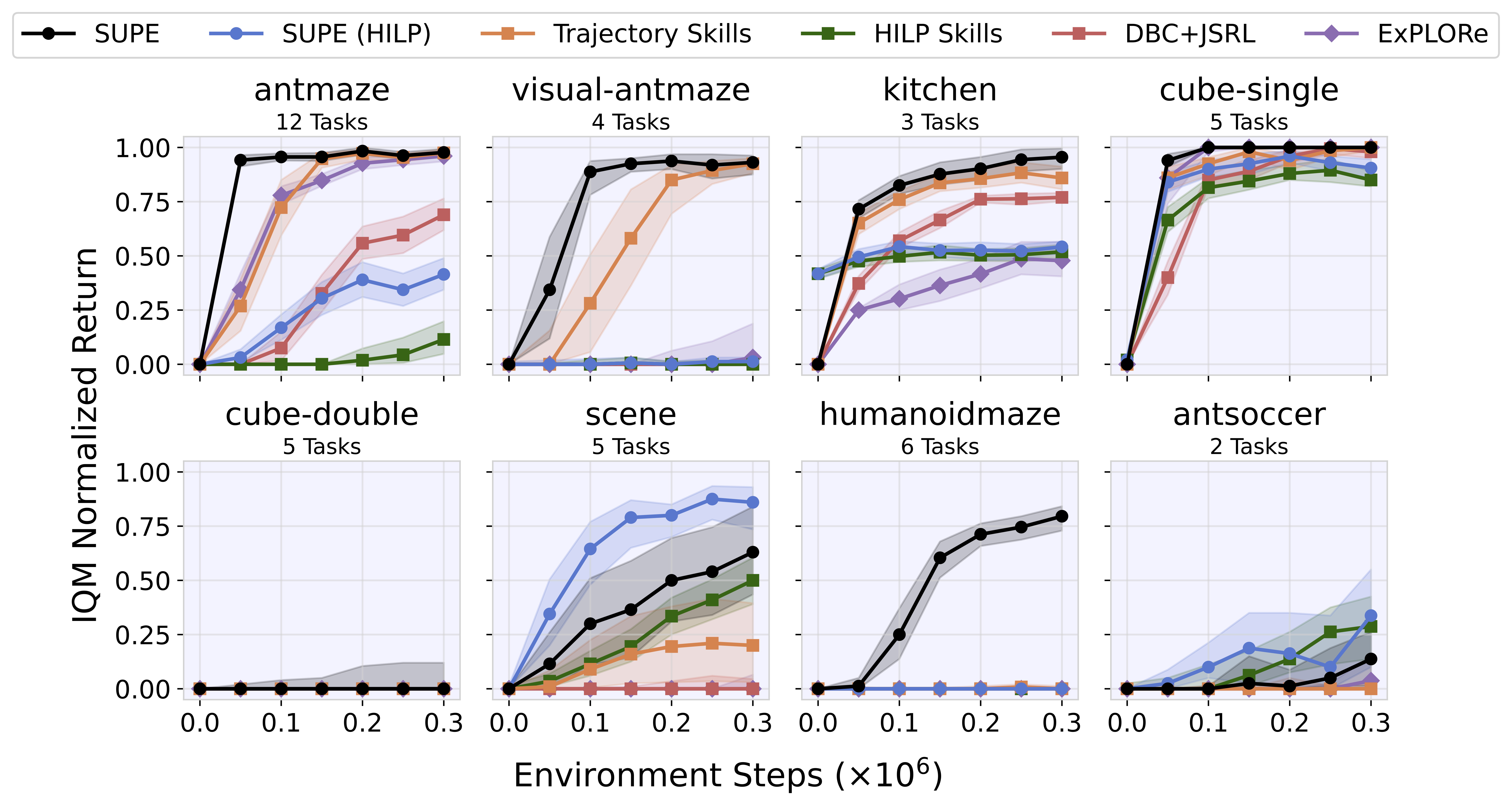
We evaluate our method across a suite of eight domains consisting of 42 sparse reward, long-horizon tasks. DBC + JSRL is a simple baseline that does not use optimistic labeling or skill pre-training. It performs reasonably well on easier tasks but struggles on more challenging domains. ExPLORe (Li et al., 2024) adds optimistic relabelling, and performs better on easier tasks, but still struggles on challenging tasks like scene and humanoidmaze. Trajectory Skills and HILP Skills are two baselines that pretrain skills but do not use offline labelling. Trajectory Skills uses the same VAE skill extraction method (Ajay et al., 2021) as SUPE, and HILP Skills learns skills which traverse a Hilbert space (Park et al., 2024). Both methods perform better on more challenging tasks like scene, but struggle on humanoidmaze. Finally, SUPE and SUPE (HILP) are variants of our method which do both skill pretraining and optimistic relabelling. SUPE uses the same skill pretraining as Trajectory Skills, and SUPE (HILP) uses the skill pretraining method of HILP Skills. We see that SUPE (HILP) performs the best on scene and antsoccer, and SUPE performs the best on all other environments. This highlights the importance of using offline data twice, both for skill-pretraining and as additional off-policy data during online learning.
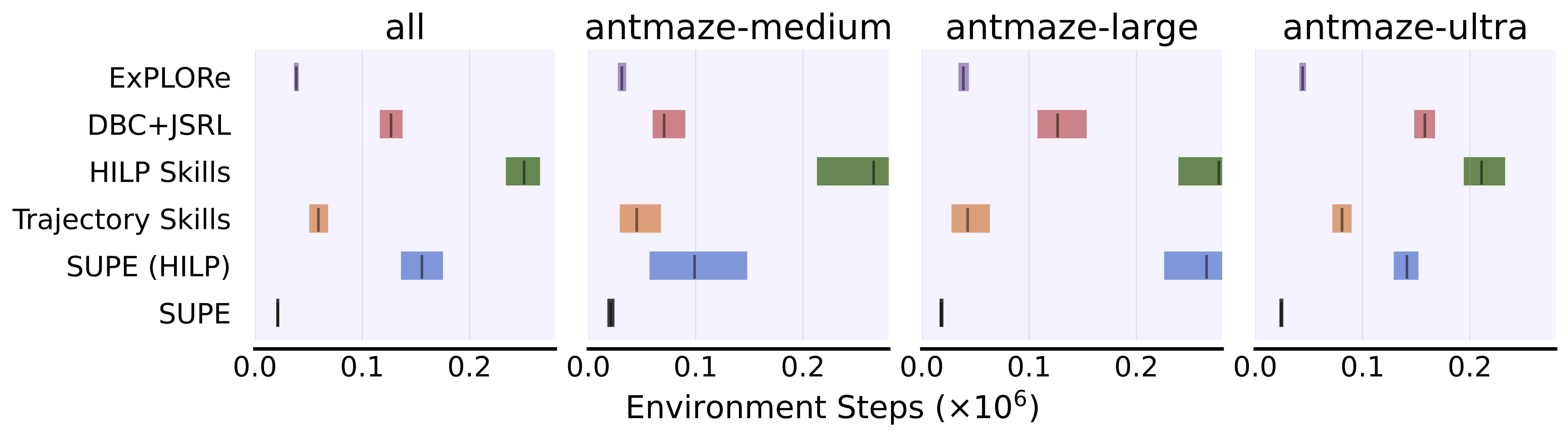
To disentangle the speed of policy learning from the sample efficiency of exploration, we look at first goal reach times in antmaze. We see that our method is consistently the fastest in each maze, averaging across 4 different goals per maze.
@inproceedings{wilcoxson2025leveraging,
title={Leveraging Skills from Unlabeled Prior Data for Efficient Online Exploration},
author={Wilcoxson, Max and Li, Qiyang and Frans, Kevin and Levine, Sergey},
booktitle={International Conference on Machine Learning (ICML)},
year={2025},
}