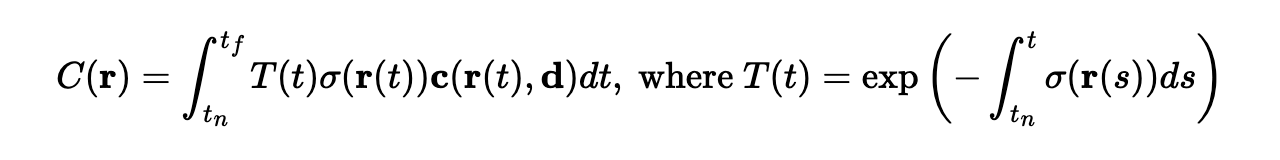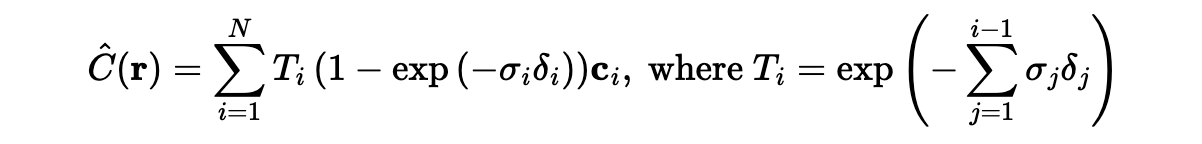In this project, we implement a neural radiance field, which is a method for using a neural network to synthesize novel views of a 3D object using pictures from several calibrated cameras. We will first do a PyTorch exercise of fitting a network to a 2D image, and then implement a neural radiance field. We will also experiment with changing the background color for the 3D render.
Part 1: Fit a Neural Field to a 2D Image
In this section, we want to train a neural network to fit two a 2D image. The input of the network is the pixel coordinates, normalized between 0 and 1. The output is the RGB pixel value at that coordinate. To add inductive bias that makes it easier for the network to understand the meaning of the position indices, we use sinusoidial positional encoding, where we apply sinusoidal functions of different frequencies to our input and concatenate these to the input.
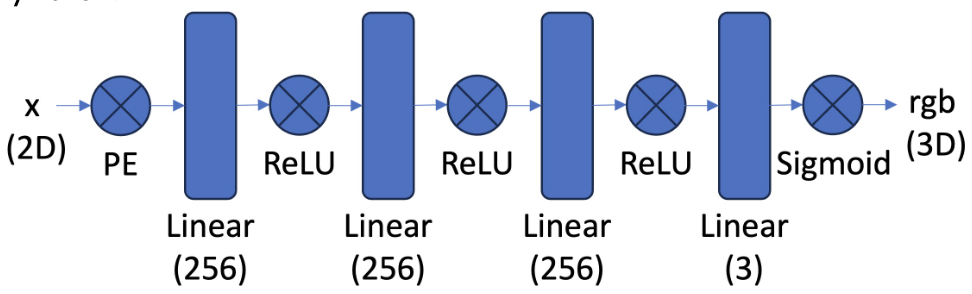
For the architecture, we do a simple MLP, where we first embed the input in the positional encoding, and then pass it through a number of fully connected layers with hidden dimension of 256 and ReLU activations. Finally, we have one last linear layer to a dimension of 3 and a sigmoid activation to get outputs in the range of 0 to 1. Below is the diagram of the architecture for 3 hidden layers:
Neural Network Architecture
We tune our hyperparameters on the given image (left), and then run our model using the same hyperparameters on an image of my dog, Bear (right). Here are the two original images for reconstruction:
Given ImageBear (My Dog)
Next, we visualize the image reconstruction for different hyperparameter choices at different training iterations. We train for 1000 iterations total, batch size of 10,000 pixels, and a positional encoding dimension of 10. We use Adam as our optimizer. We try 2, 3, and 4 hidden layers of width 256, and learning rates of 0.01, 0.001, and 0.0001. Below we visualize the training progress on the provided image for the different hyperparameter configurations at different training steps:
Iteration 0
Iteration 100
Iteration 200
Iteration 500
Iteration 1000
num_layers=2, lr=0.01
num_layers=2, lr=0.001
num_layers=2, lr=0.0001
num_layers=3, lr=0.01
num_layers=3, lr=0.001
num_layers=3, lr=0.0001
num_layers=4, lr=0.01
num_layers=4, lr=0.001
num_layers=4, lr=0.0001
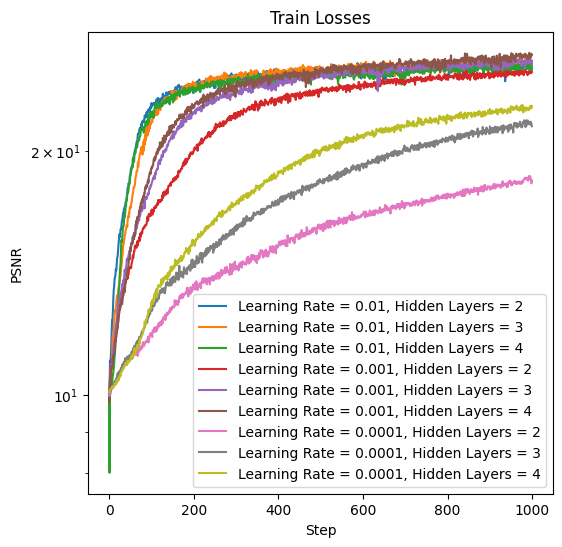
We can see that a larger learning rate is much better, and that more layers seems to help a bit too. This becomes more clear looking at the training loss curves, pictured below:
Hyperparameter Sweep on Given Image
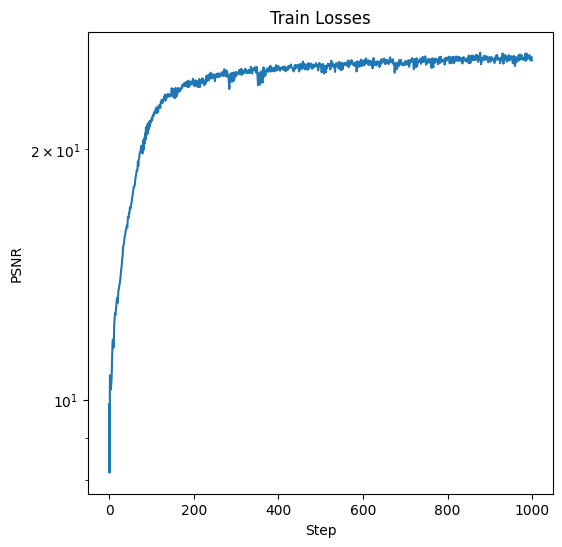
In the above graph, we see that a learning rate of 0.01 is the most important hyperparameter. More layers seems slightly better, but also increases the computational cost. From this sweep, we select 3 layers and a learning rate of 0.01. This gives the following training curve with these hyperparameters:
Training Loss for Given Image
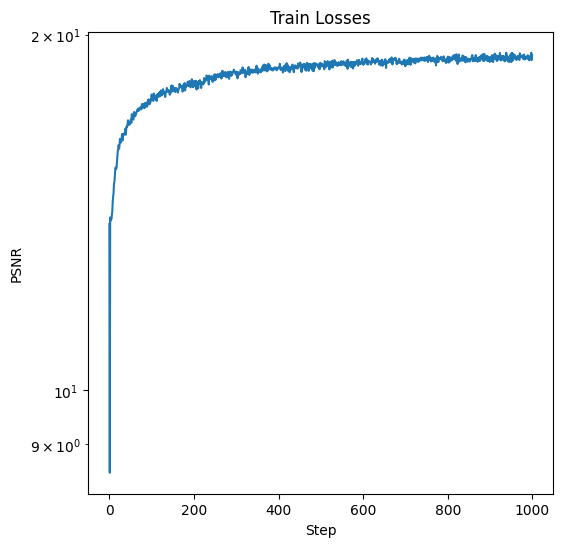
Finally, we can apply these hyperparameters to another image, one of my dog, Bear. This gives the following training progress and training curve:
Iteration 1
Iteration 100
Iteration 200
Iteration 500
Iteration 1000
Training Loss for Image of Bear
Part 2: Fit a Neural Radiance Field from Multi-view Images
We will render a view of a Lego bulldozer.
Part 2.1: Create Rays from Cameras
We first need to implement a function to change coordinates from camera frame to the world frame. We have the transformation matrix, so implementation-wise, we just need to convert to homogeneous coordinates, perform the multiplication with torch.bmm to make it batched, and then return the answer in non-homogenuous coordinates.
Then, we need to implement the transformation from pixel to camera coordinates, which just involves multiplying by the inverse camera intrinsics matrix and some scaling factor s. We also convert the pixels to homogenuous coordinates.
With these transformations implemented, we need to convert a pixel to the ray that goes through that pixel. The origin of the ray is just the translation vector in the camera to world matrix we have access to from camera calibration. For the direction, we can convert the pixel to world coordinates by chaining the above two function transformations, and then normalizing the direction of that coordinate from the ray origin to make it unit norm.
Part 2.2: Sampling
We sample N//M rays from each of the M images, where N is the batch size. In each image, we pick a pixel at random, and sample the ray corresponding to that pixel. We add 0.5 to our pixel coordinates because it is convention that the ray goes through the center of the pixel.
Now that we have rays, we need to sample points on the ray. We sample uniformly for num_samples from a distance of 2.0 to 6.0 from the origin of the ray. For this project, we use 64 samples. To avoid overfitting, we need to add a uniform perturbation so the network learns to predict values throughout the whole space. To assure that there are no gaps, I set the width of the perturbation, t_width, equal to (far - near)/num_samples = 0.0625.
Part 2.3: Putting the Dataloading All Together
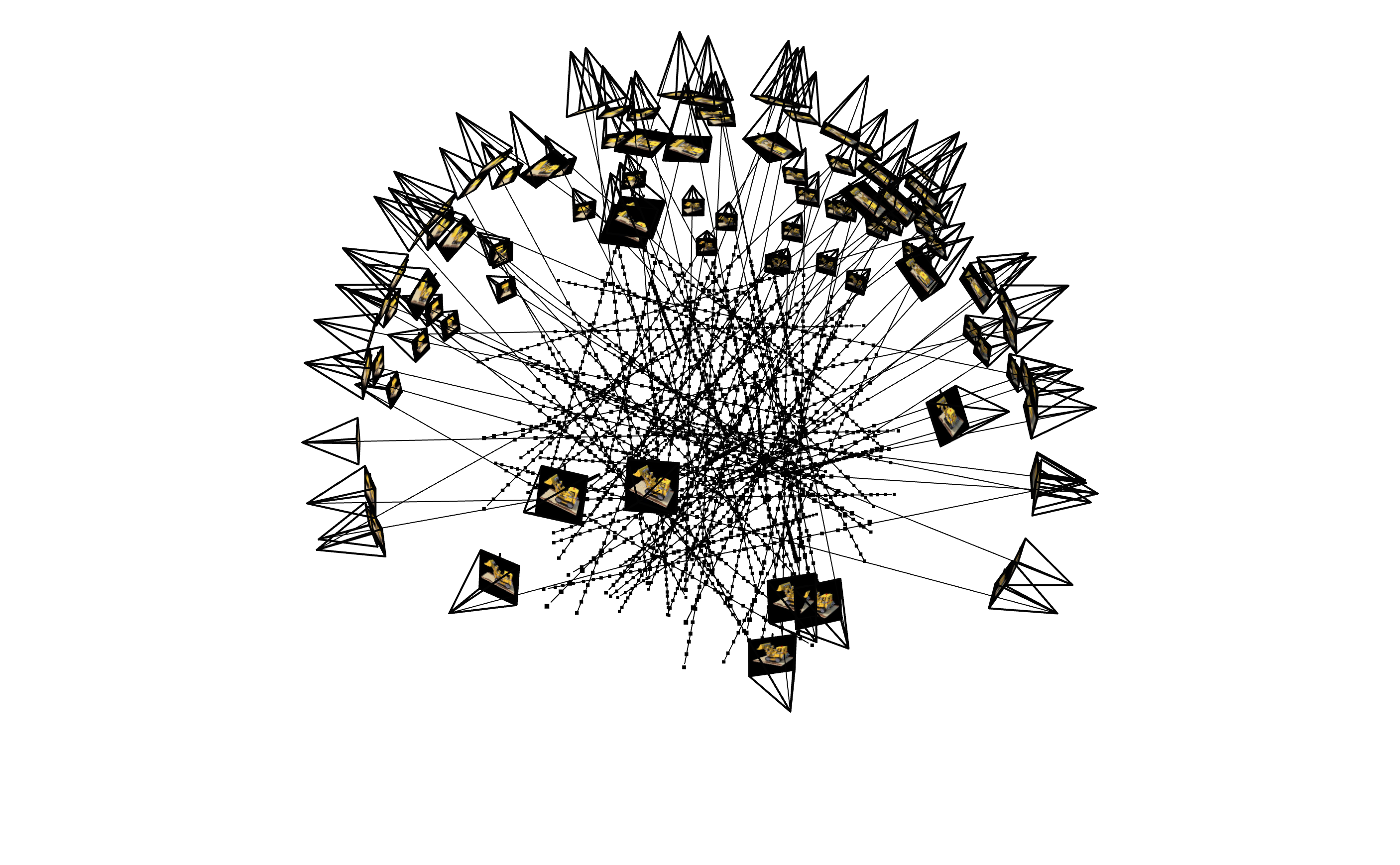
To verify that everything in the above parts has been implemented correctly, we can visualize rays sampled through this process. We show the visualization of 100 rays sampled from both 1 camera and all cameras below:
Visualization of Rays Sampled From First Camera Visualization of Rays Sampled from All Cameras
Everything looks good, as all rays are going through the camera frustum, and if we look at the single camera visualization, all rays are going through a single image plane.
Part 2.4: Neural Radiance Field
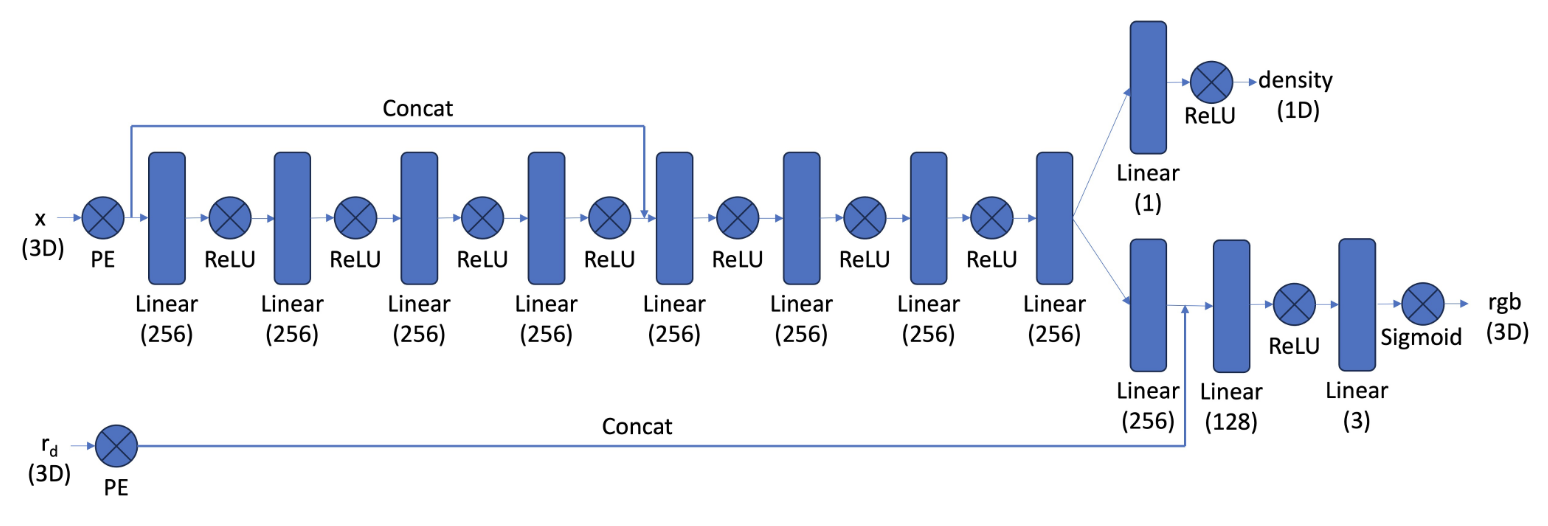
We use a similar network architecture as the 2D case, except now our network needs to take in a 3D coordinate in world space and the direction of view. It will now output an RGB value and a density to support volumetric rendering later. Since this is a harder task, we add additional layers. We do positional encoding for both inputs, and use an L = 10 for the world coordinates and L = 4 for the direction. By using a ReLU activation for the density, we assure that the density is valid. We still have a sigmoid activation for the RGB. A complete diagram of the network architecture is shown below:
NERF Neural Network Architecture
Part 2.5: Volume Rendering
To use these density and RGB estimates to get pixels, we need to use volumetric rendering. The volumetric rendering equation is shown below:
We use a discrete approximation:
In this equation, T_i is the probability of the ray not terminating before sample i, and 1 - exp(-sigma_i*delta_i) is the probability it terminates at sample i. We can implement this in PyTorch, and it is differentiable. Delta_i is supposed to be the difference in the time between adjacent samples. In my implementation, I use the actual delta between the noisy sampling times, so the augmentation doesn't change the correctness of the answer. Based on my understanding of the description in the original NERF paper, this seems to match their implementation.
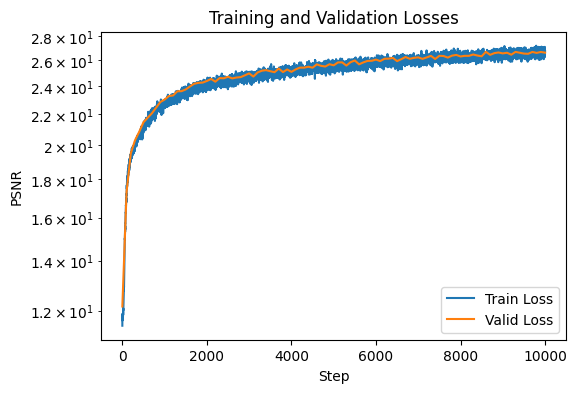
We train for 10000 iterations, a batch size of 10000, and learning rate of 5e-3. We visualize the training process below:
We can also visualize the PSNR on both the training set and validation set:
Training and Validation PSNR for NERF
We see that there is no significant overfitting, and that our data augmentation is functioning well.
Now, we can render a variety of novel views in sequence to create a video going around the object. This just involves doing the render for several different camera positions and then playing them in sequence. We visualize the video below:
Performance After 10000 Training Iterations
Part 2.6: Bells and Whistles
For the Bells and Whistles, we chose changing the background color. This just requires adding one more point far from the origin in the volumetric rendering of the desired color with high density. That way, if there is nothing with density that is blocking it (an object), the color will be that background color. Making this change to the rendering equation helps produce the desired result, however there is a small problem. Some background pixels are black with nonzero density, and this gets worse as the network is trained longer. My hypothesis is that this is because both solutions are valid from the perspective of satisfying the training loss, and as we continue to train we "overfit" to the background color and predict the color with density instead of nothing with no density. This might because this is easier to learn, since it requires just predicting the background color black with high density at one point, rather than learning to have no density throughout the entire ray. Below, I visualize rendering videos with a blue background color for checkpoints at different steps in training:
1000 Iterations 2000 Iterations 10000 Iterations
To make this better, I tried adding regularization to give the model bias to predict zero density when possible by adding a small penalty proportional to the l2 norm of the density predictions. I used a coefficient of 1e-6, adding 1e-6 times the l2 norm of the density predictions for the batch. This helped reduce this problem, but it is not perfect, as some areas are now transparent that should not be. Additionally, some areas near the edge of the bulldozer still become colored black. If more compute was available, perhaps better tuning of this parameter could help.
Performance after 10000 Training Iterations, With Density Penalty
I also tried augmentation during training of changing the background to a variety of different colors to avoid overfitting to the background color, and changing the rendering accordingly. Unfortunately, this only works if you can select all of the background, and I was unable to select the background region inside areas of the bulldozer, just those near the edges. Because of this, this approach actually caused the model to learn to predict solid black in those regions, since otherwise it was not possible to match the fixed ground truth value in those regions with the changing render background color.