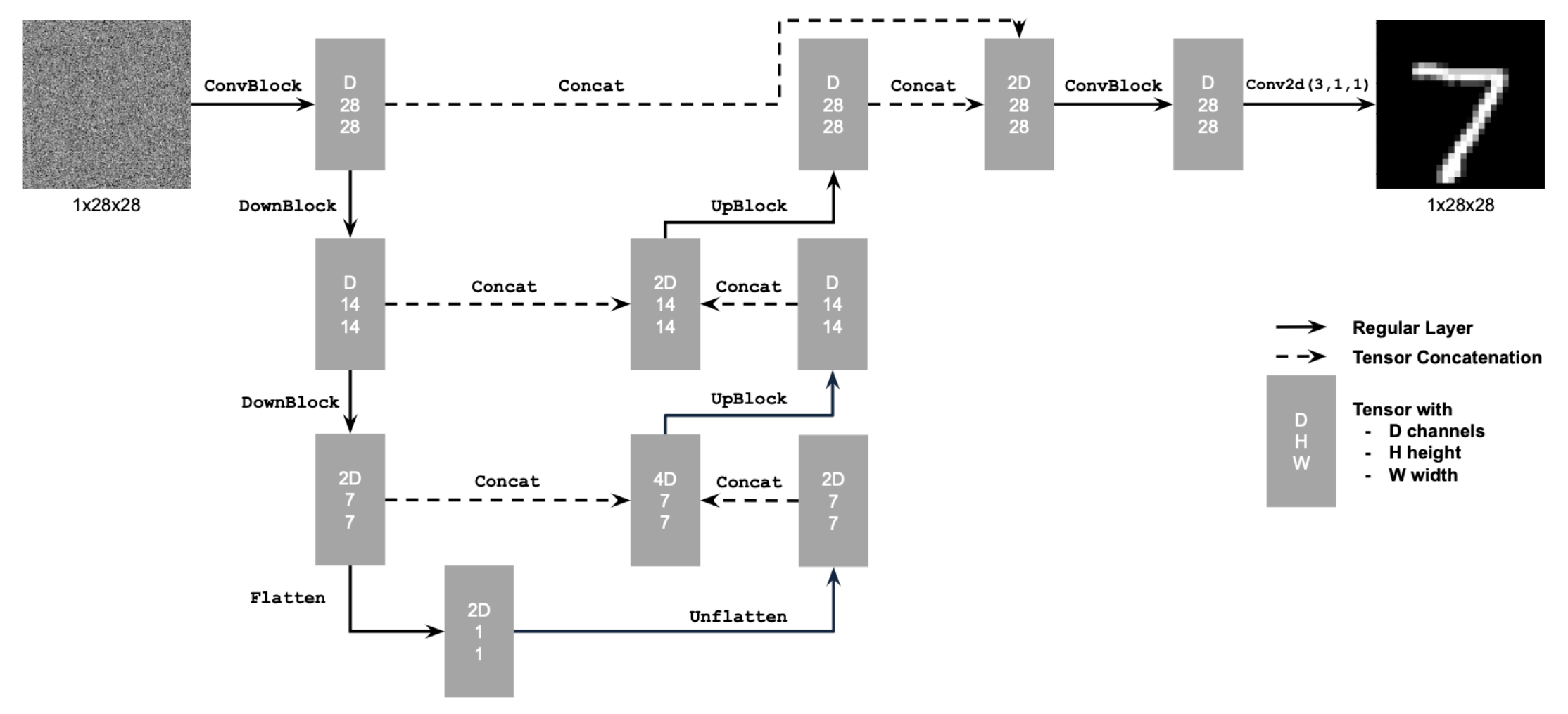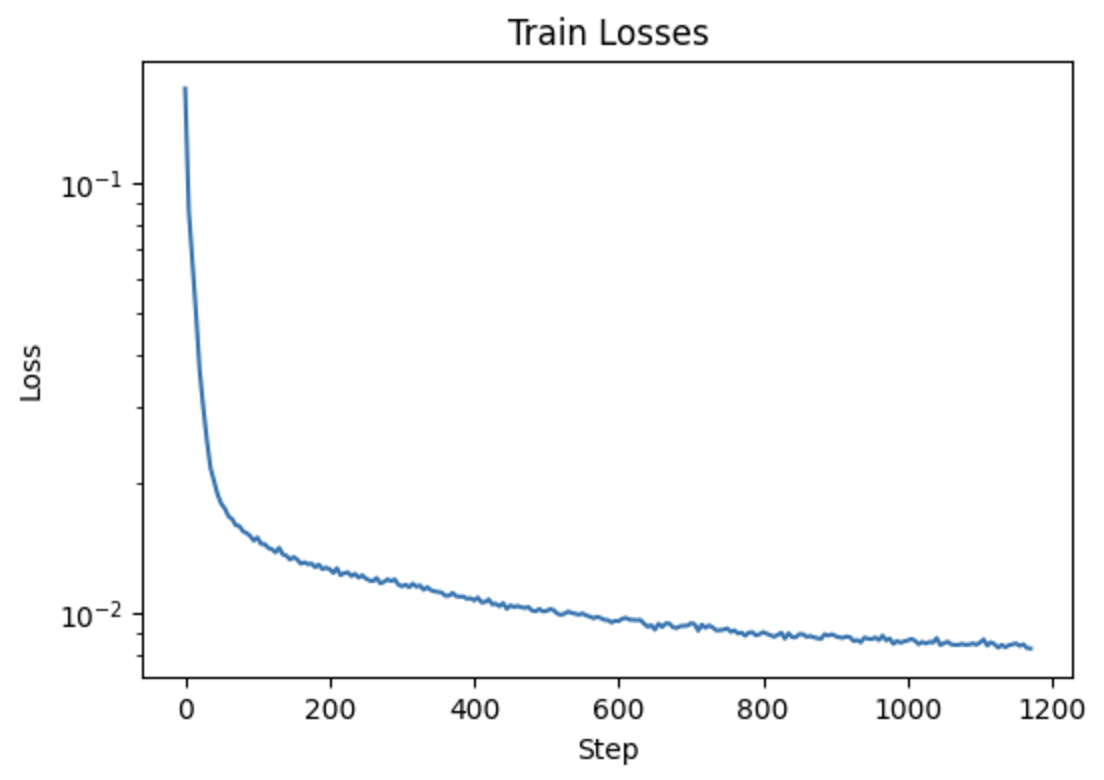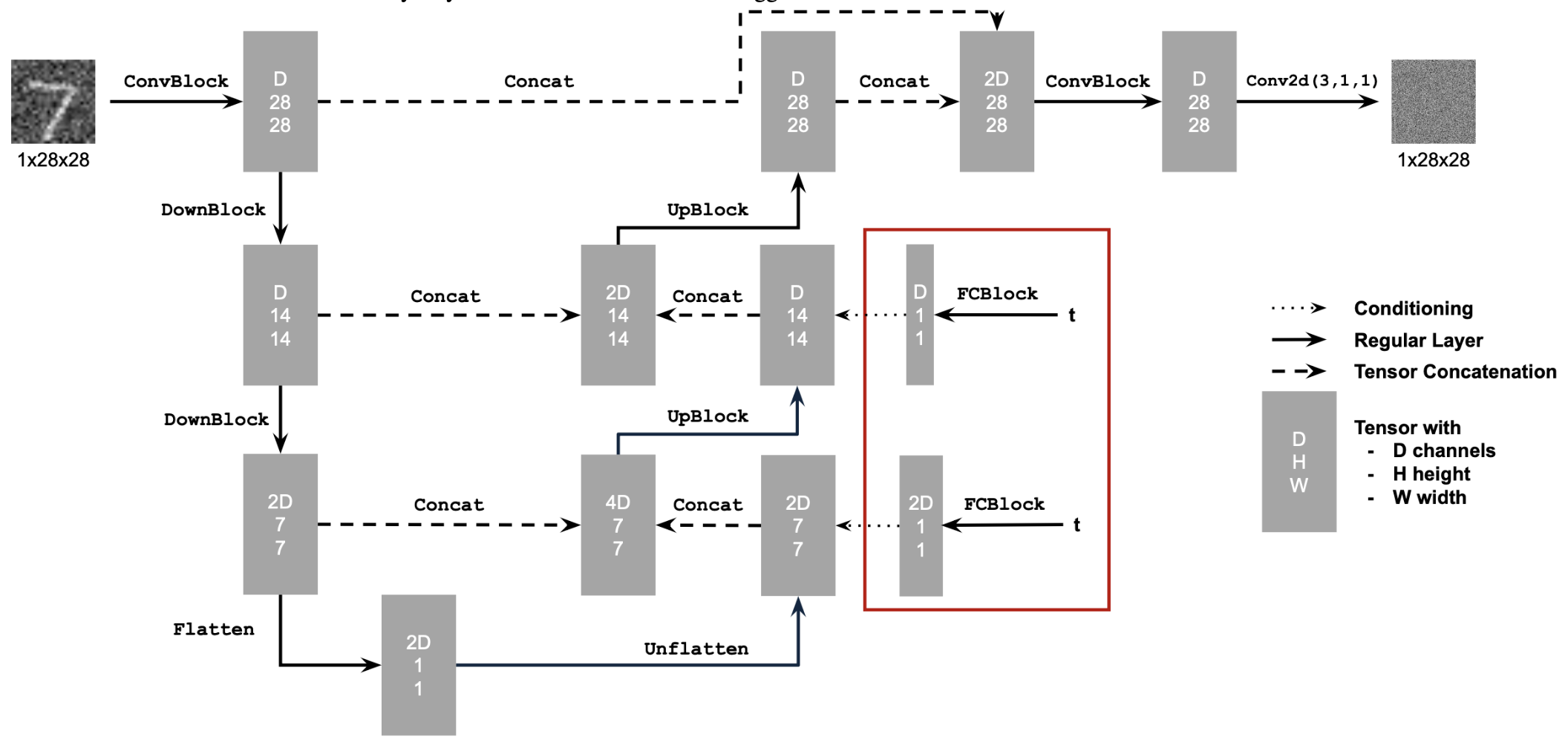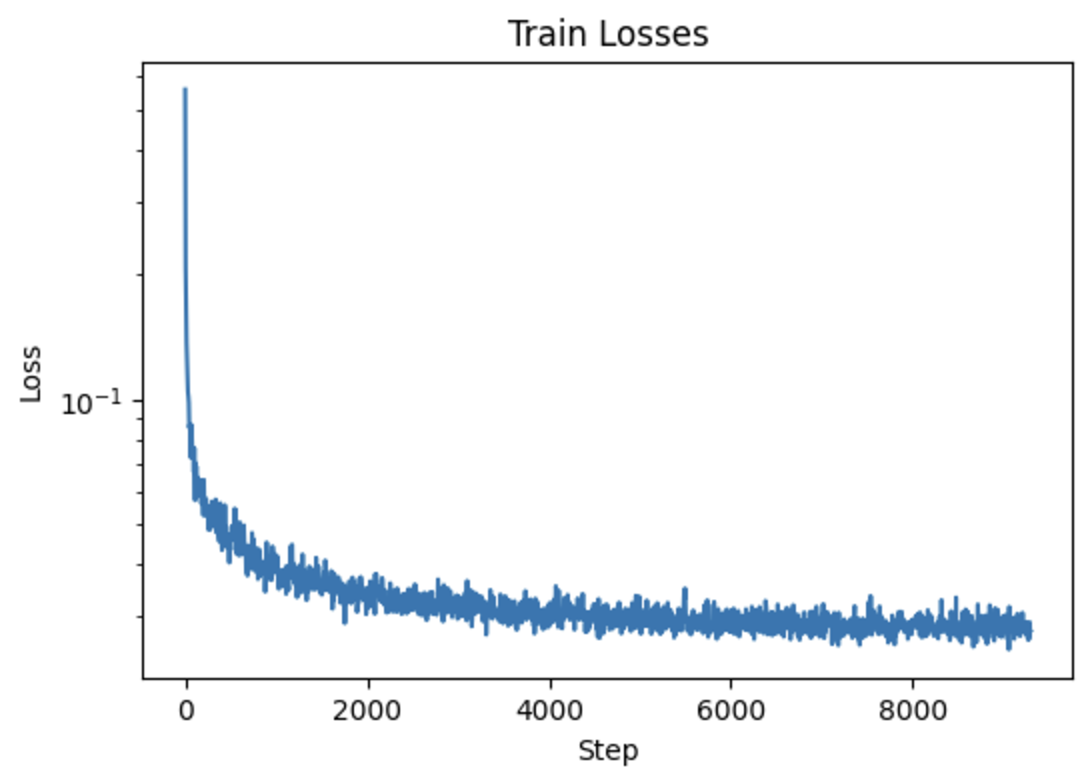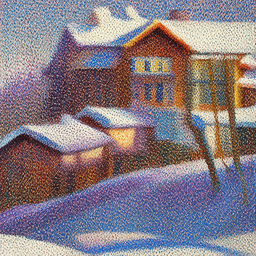





| Prompt | 10 Inference Steps | 20 Inference Steps |
|---|---|---|
| an oil painting of a snowy mountain village | |
|
| a man wearing a hat | |
|
| a rocket ship | |
|
| t = 0 | t = 250 | t = 500 | t = 750 |
|---|---|---|---|
 |
 |
 |
 |
| t = 250 | t = 500 | t = 750 | |
|---|---|---|---|
| Noisy Image | |
|
|
| Denoised Image |  |
 |
 |
| Original Image | |||
|---|---|---|---|
|
| t = 250 | t = 500 | t = 750 | |
|---|---|---|---|
| Noisy Image | |
|
|
| Denoised Image |  |
 |
 |
| Noisy Campanile at t = 90 | Noisy Campanile at t = 240 | Noisy Campanile at t = 390 | Noisy Campanile at t = 540 | Noisy Campanile at t = 690 |
|---|---|---|---|---|
 |
 |
 |
 |
 |
| Original | Iteratively Denoised Campanile | One-Step Denoised Campanile | Gaussian Blurred Campanile |
|---|---|---|---|
|
 |
 |
 |
| Sample 1 | Sample 2 | Sample 3 | Sample 4 | Sample 5 |
|---|---|---|---|---|
 |
 |
 |
 |
 |
| Sample 1 | Sample 2 | Sample 3 | Sample 4 | Sample 5 |
|---|---|---|---|---|
 |
 |
 |
 |
 |
| SDEdit with i_start=1 | SDEdit with i_start=3 | SDEdit with i_start=5 | SDEdit with i_start=7 | SDEdit with i_start=10 | SDEdit with i_start=20 | Original Image |
|---|---|---|---|---|---|---|
 |
 |
 |
 |
 |
 |
|
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
| SDEdit with i_start=1 | SDEdit with i_start=3 | SDEdit with i_start=5 | SDEdit with i_start=7 | SDEdit with i_start=10 | SDEdit with i_start=20 | Original Image |
|---|---|---|---|---|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
| Original Image | Mask | Reconstructed Image |
|---|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
 |
| Prompt | SDEdit with i_start=1 | SDEdit with i_start=3 | SDEdit with i_start=5 | SDEdit with i_start=7 | SDEdit with i_start=10 | SDEdit with i_start=20 | Original Image |
|---|---|---|---|---|---|---|---|
| a rocket ship |  |
 |
 |
 |
 |
 |
|
| a photo of a dog |  |
 |
 |
 |
 |
 |
|
| a photo of the amalfi coast |  |
 |
 |
 |
 |
 |
|
| Prompt | Flipped Prompt | Weight | Image | Flipped Image |
|---|---|---|---|---|
| an oil painting of people around a campfire | an oil painting of an old man | 0.75 |  |
|
| a photo of a hipster barista | an oil painting of a snowy mountain village | 0.65 |  |
|
| a lithograph of waterfalls | a lithograph of a skull | 0.75 |  |
|
| Low Freq. Prompt | High Freq. Prompt | Image |
|---|---|---|
| a lithograph of a skull | a lithograph of waterfalls |  |
| a lithograph of a cat | a lithograph of a dog |  |
| a lithograph of a man | a lithograph of a skull |  |